【機械学習】初心者がKaggleのtitanicで勉強してみた
機械学習はじめました!
今や様々な分野で活用される機械学習。
仕事で必要になるのはもちろんだが、趣味としてやっても非常に面白そうな分野だと思っている。
実はこれまでも参考書を読んだり、ちょこちょこと勉強はしていた。 何冊か参考書を読んでなんとなく概要?程度はわかってきた気がするので、このブログでいろいろと備忘録も兼ねてまとめていこうと思う。
今回の記事では、データから実際に予測を立てるまでの方法・過程をまとめます。
手順としてはこんな感じ
- データをみる!
- 前処理
- モデルを選定
- モデルチューニング
- 結果整理
長くなりそうなので、分けて記事にあげていく予定。 Kaggle と Python の詳しい使い方についてはここでは言及しない。
(追記) 続き記事はこちらです。
- 【機械学習】初心者が Kaggle の titanic で勉強してみた(前処理編)
- 【機械学習】初心者が Kaggle の titanic で勉強してみた(アルゴリズム選定編)
- 【機械学習】初心者が Kaggle の titanic で勉強してみた(モデル評価編)
Kaggle について
Kaggle は機械学習を勉強している人なら一度は聞いたことがあるはず。 簡単に言うと与えられたデータに対して各々が機械学習を行って、性能を競いあうものだ。
これだけ聞くと自分のような初心者にはハードルが高そうだが、そんなことはない。
Kaggle には入門者向けのデータも用意されていて、少ない特徴量かつわかりやすい問題設定のものがいくつかある。
さらにいいのは、それら入門者向けのデータを用いて、他の人がどうやっていい性能を出したのか見ることができることだ。
コードの書き方、特徴量設計などの手法を学べで非常に参考になる。
ということで、今回はこの Kaggle で「Titanic: Machine Learning from Disaster」にチャレンジしていく!
この Titanic というデータセットは初めての Kaggle と聞いたらほとんどの人が Titanic と答えるくらい初心者御用達のもの。
タイタニック 生存者予測の概要
Titanic データセットの詳しいことは ↑ のリンクに書いてあるのでここでは簡単に説明する。
まず、訓練用とテスト用の csv があらかじめ与えられる。 説明変数(特徴量)は 12 個。そのうち一つが目的変数になる。
この目的変数は 0 か 1 の値で乗客が生き残ったか否かを示す。
つまり、これが教師データに該当するので、他の説明変数からモデルを構築し、テストデータの 0 か 1 の値を予測すればよいということだ。
データをみる!
まずはデータを眺めて、どんなデータがあるか、データ間の関係などを理解する。
データは csv で与えられているので、pandas を用いることで簡単に可視化できる。
import pandas as pd
TRAIN_DATA_FILE = "train.csv"
TEST_DATA_FILE = "test.csv"
## 与えられたデータを読み込みざっと見る
train_data = pd.read_csv(TRAIN_DATA_FILE)
train_data.head()
どんなデータがあるかなんとなくわかる。
次はもう少し詳しく各列についてみてみる。
## info()で各columnの情報をみる
train_data.info()
ここでは、カテゴリ変数の有無と欠損値があるかないかをみる。
AgeとCabinの欠損が多いことがみてとれる。
欠損値があると後ろの処理で使えないので、欠損値は適切に処理する必要がある。 したがって、どの列に欠損があるのか覚えておく。
また、カテゴリ変数(object とかいてるもの)も必要に応じて数値に直さなくてはならないので覚えておく。
今更だが、わかりづらいであろう列の説明だけを以下にしめす。
- SibSp : # of siblings / spouses aboard the Titanic (兄弟の数 / 配偶者)
- Parch : # of parents / children aboard the Titanic (両親の数 / 子供)
- Pclass : Ticket class (1 = 1st, 2 = 2nd, 3 = 3rd)
次は、数値データのみをヒストグラムにして、視覚的にわかりやすくしてみる。
import matplotlib.pyplot as plt
## ヒストグラムでデータの概略をつかむ
train_data.hist(bins=50, figsize=(20,15))
plt.show()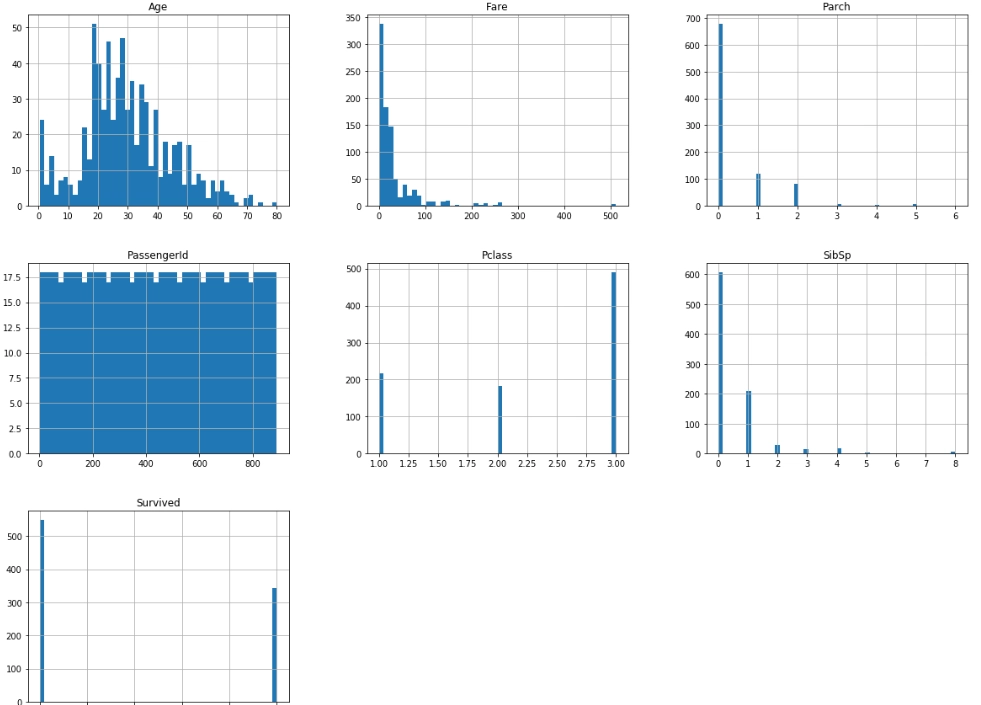
ふむふむ。ヒストグラムにするとかなりみやすい。
Ageは 20~30 代が多い、Survivedは生存できなかったほうが割合としては多いなど、傾向が一目でわかる。
次にみたくなるのは各データの相関だ。 このデータ相関は、あとで説明変数を選択・除去する際に参考になる。
まずは、目的変数と相関の高いデータは重要なはずなので目的変数との相関を見る。
corr_matrix = train_data.corr()
corr_matrix["Survived"].sort_values(ascending=False)
どうやらFareに相関があるらしい(金持ちの方が助かった?)。
あとはPclassにも相関がある。おそらくFareと関連するからだろうということが想像できる。
そうなるとFareと相関があるものが気になってくる。
## 料金との相関
corr_matrix["Fare"].sort_values(ascending=False)
やはりPclassとはかなり強い相関がある。
Survived以外では、Parchと相関があるようだ。
子供と両親の数で料金が変わるからだろうか?
次はParchの相関をみる。
## 子供あたりの親の数との相関
corr_matrix["Parch"].sort_values(ascending=False)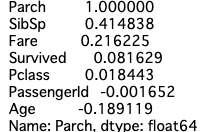
SibSpと強い相関がある。これも納得の相関な気がする。
さて、ここまでで以下のようななことがわかった。
- どんなデータがあるか
- ざっくりとした数値データの傾向
- 欠損値があるのはどの列か
- カテゴリ変数の有無
- 各データの相関関係
次は、これらの情報を踏まえて実際にデータを適した形に処理していく。
まとめ
これまでの学習は、参考書をみながらただ写していただけなので、今回実際に問題が与えられても最初になにをやったらいいのか戸惑った。
ネットにあがってる解答は自分で一回書いてから!と決めていたので、ここまでやるだけでもそこそこ時間がかかった。
解答は見ずに、下にあげた参考書を見ながらなにをやったらいいのか考え、やった結果に対して理解し、次のアクションを考える作業は非常に勉強になった。
少し、長くなったので続きの前処理編の記事は次回!
参考
ここにあげた以外でも Kaggle を漁れば良質なコードと説明があがってると思う。 先人に感謝です。
あと、この二冊の本はマジでおすすめです。
参考 web サイト