【機械学習】初心者がKaggleのtitanicで勉強してみた(アルゴリズム選定編)
はじめに
初心者が Kaggle の Titanic をやってみた 3 回目アルゴリズム選定編やります!
(↓ これまでの記事)
【機械学習】初心者が Kaggle の titanic で勉強してみた
【機械学習】初心者が Kaggle の titanic で勉強してみた(前処理編)
第 3 回目にしてようやく機械学習の部分です。
今回は、前回までで前処理したデータを使って機械学習アルゴリズムを利用して実際に生存者予測を行います。
その過程で、交差検証やホールドアウトにも触れます。
いや〜長かった。
調べながらやっていたらこんなに時間がかかってしまった。
しかも、やってみてわかったが調べれば調べるほどわからないことが増えていくという。。。
世の機械学習エンジニアはどうやって勉強してるんだろう。
ゆくゆくは論文のまとめだったりをやっていきたいが道のりは長い。
アルゴリズム選定
機械学習には様々なアルゴリズムが存在する。問題を解決するには、解きたい問題に適したアルゴリズムを選ぶ必要がある。
さらにアルゴリズムを選ぶ為には、どんな問題なのか、どんなアルゴリズムなのかを知る必要がある。
そこで、もう一度自分たちがどんな問題を解決しようとしているのか見直してみる。
今回、最終的にやりたいことは生存者予測である。つまり生き残るか否か、0 か 1 かを予測することだ。
つまり、これは 2 値分類問題だと考えられる。 そして、与えられたデータには乗客の情報とその乗客が生き残ったかどうかの情報がある。
ということは、この問題は機械学習の中でも教師あり学習と呼ばれる学習手法に分類されるものだとわかる。
もはや説明するまでもないと思うが、自分のために書いておくと機械学習は大きく分けて以下の二つの学習手法がある。
- 教師あり学習
- 教師なし学習
問題を解く際には、解こうとしている問題が教師あり学習で解けるのか教師なしでやらなければならないのか考える必要がある。
自分は、正解が用意されていれば教師あり学習だと単純に考えている(これでよいのか?)。
ここまでを整理すると、今回の問題は2 値分類の教師あり学習であることがわかった。
この問題が解けるアルゴリズムを調べると以下のものがあった。
- k-最近傍法
- ロジスティック回帰
- ナイーブベイズ
- 決定木
- サポートベクタマシン
- ニューラルネットワーク
- AdaBoost
- ランダムフォレスト
他にもあった気がするが多すぎてツライのでこれだけあげた。
特にサポートベクタマシンは難しく種類もいくつかあるため調査は今後の課題にしとく。
これでようやく使えそうなアルゴリズムが揃った。
次はこれらのアルゴリズムをテストして精度のいいものを選定する。
アルゴリズム評価方法
次はアルゴリズムを選定するために、訓練データをまた検証用と訓練用にわける。
ただ、ここで参考書などを読んでて頭がごっちゃになったので言葉を整理したい。
自分が混乱したのはホールドアウトと交差検証についてだ。
アルゴリズムを選定する方法として、これらがよくあげられるが何がなんのためのものなのか、理解があいまいになっていた。 それらについて説明しておく。
機械学習ではよく訓練データとテストデータのように分けられているのをよく見かけると思う。
実際、今回の Titanic でも提供されたデータは訓練用とテスト用に分けられている。なぜこのように分けるかというと、機械学習では最終的に未知のデータに対する精度が要求されるからだ。
そこで、擬似的に未知のデータを作り出す方法として、今あるデータを訓練とテスト用に分ける交差検証と呼ばれる手法が一般的に用いられる。
交差検証には大きく分けて二つの手法がある。ホールドアウトとk-分割交差検証だ。
ホールドアウトは先ほど例にあげたもので、事前に訓練とテスト用にデータを分ける方法だ。
k - 分割交差検証は、全体を k 分割し、それらのうち一つをテストデータとして扱い訓練する。これを k 個それぞれに行うのが k - 分割交差検証になる。
両者の違いとしては、ホールドアウトだと選んだテストデータによっては偶然いい性能がでるという可能性があるが、k-分割の方では、その可能性を低くできる。
アルゴリズム検証方法
アルゴリズムを検証するために、訓練データをさらに検証用と訓練用にわける。
from sklearn import model_selection, metrics
# testデータで試す前に訓練データでいくつかモデルを試す
# cleaned_data:前処理済みデータ(ndarray)
# y:正解データ
X_train, X_test, y_train, y_test = model_selection.train_test_split(cleaned_data, y, random_state=1)これでついにアルゴリズムにデータをいれていく!!
今回は結果を見比べたかったのでこんな感じにしてみた。
ニューラルネットワークはライブラリの使い方を勉強しなきゃなので、また今度やります。。。
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier # K近傍法
from sklearn.tree import DecisionTreeClassifier # 決定木
from sklearn.ensemble import RandomForestClassifier # ランダムフォレスト
from sklearn.ensemble import AdaBoostClassifier # AdaBoost
from sklearn.naive_bayes import GaussianNB # ナイーブ・ベイズ
import pickle
classifiers = [
LogisticRegression(),
KNeighborsClassifier(),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GaussianNB(),
]
names = ["Logistic Regression", "Nearest Neighbors",
"Decision Tree","Random Forest", "AdaBoost", "Naive Bayes"]
# アルゴリズムを順に実行
result = []
for clf, name in zip(classifiers, names):
clf.fit(X_train, y_train)
score1 = clf.score(X_train, y_train)
score2 = clf.score(X_test, y_test)
fname = name + "{}".format(".pickle")
result.append([score1, score2])
with open(fname, 'wb') as f:
pickle.dump(clf, f)
print(name)
df_result = pd.DataFrame(result, columns=['train', 'test'], index = names)
df_result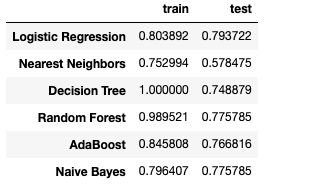
検証データでの結果をみると、Logistic Regressionが一番高く、それ以外は検証データの結果をみるにそこまで違いはなさそう。
まあ、とりあえず結果が一番いいLogistic Regressionと有名なRandom Forestを選択することにする。
これでアルゴリズムを選定できたぞ!
次は、パラメータチューニングだ!
パラメータチューニング
アルゴリズムには利用者が自分で設定しなければいけないパラメータが存在する。
それらのパラメータは非常に重要でアルゴリズムの性能を大きく左右する。
そこで、上で選定したアルゴリズムについてもパラメータチューニングを行っていく。
これには、sklearn のグリッドサーチを用いる。
グリッドサーチでは、パラメータととりうる値を与えることで、それらの組み合わせすべてを試して、ベストな組み合わせを算出してくれる。
さっそくロジスティック回帰とランダムフォレストで試してみる。
from sklearn.model_selection import GridSearchCV
# ロジスティック回帰のパラメータ
parameter={"C":[10**i for i in range(-2,4)],"random_state":[1],}
grid_search = GridSearchCV(LogisticRegression(), parameter, cv=5)
grid_search.fit(X_train, y_train)
print("Best parameters : {}".format(grid_search.best_params_))
print("Best cross-validation score : {:.3f}".format(grid_search.best_score_))
結果をみると、チューニング後と変わってない??
少し違うパラメータでやってみる。
parameter={"C":[i for i in range(1, 20 )],"random_state":[1],}どうやらこれが現状のベストのようだ。
思ったよりかなりしょぼい。なにか間違っている気がする。
いったんランダムフォレストについても同様にやっていく。
from sklearn.metrics import classification_report
# ランダムフォレストのパラメータ
# n_estimators → 決定木の数
# max_features → 決定木の特徴量の数
# random_state → 乱数シード
# max_depth → 決定木の深さ
# min_samples_split → 決定木を分割する際のサンプル数の最小数
parameter={
"n_estimators":[i for i in range(10, 100, 10)],
"criterion":["gini","entropy"],
"max_depth":[i for i in range(1,10,1)],
"min_samples_split": [2, 4, 10,12,16],
"random_state":[3]
}
grid_search = GridSearchCV(RandomForestClassifier(), parameter, cv=5)
grid_search.fit(X_train, y_train)
print("Best parameters : {}".format(grid_search.best_params_))
print("Best cross-validation score : {:.3f}".format(grid_search.best_score_))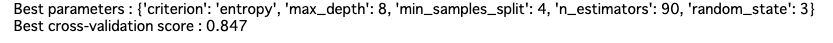
うおーーー!。こっちはめっちゃ精度上がったぞ!!
ちょっとロジスティック回帰はいったん置いといて、ランダムフォレストをベストパラメータで検証データを試していく。
rf = RandomForestClassifier(**grid_search.best_params_)
rf.fit(X_train, y_train)
test_score = rf.score(X_test, y_test)
print("Score with best parameteras : {}".format(test_score))
うーむ。よくはなったが微妙なスコア。
これは特徴量設計に立ち戻ったほうがよさそう。
検証データでいくつのスコアをだせば満足していいかわからんが 90%くらいの精度は欲しい。
パラメータチューニングしたら 95%くらいの精度になると勝手に思っていたんだがなぁ。
まとめ
今回で終わりかと思ったが道のりは長そう。
それと今回あたりからマシンパワーが欲しくなった。
ほんとはサポートベクタマシンも試してたんだが、計算が遅すぎて断念してしまった。
パソコン買うかぁ。。。
参考書籍です。