PyTorchでTensorBoardを使う方法
はじめに
どうも。おい丸です。
今回は久々に技術系の記事を書きました。
内容はPytorch での TensorBoard の使い方になります。
ちょっと前に書いた Titanic 以来の機械学習系の記事です。
TensorBoard とは
TensorBoard は、TensorFlow に付属する可視化機能です。 コマンドで起動すると、ブラウザで可視化用のダッシュボードを利用して各種結果をみることができます。
機械学習でよく可視化するエポックごとの loss や accuracy をはじめとした値を簡単に可視化することができます。
また、loss などのスカラーだけでなく、Imageやaudio、textなどに関しても簡単に可視化が可能です。
なぜ TensorBoard?
Python には matplotlib という可視化のライブラリがあるのですが、描画の設定などが若干面倒です。
私の場合は matplotlib が苦手で、いつになっても書き方を覚えられず、毎回ググってました。
一方で、TensorBoard はグラフの表示部分は自動でやってくれるので覚えることが少なく、コードの記述量も少なくて済みます。
加えて、データはファイルに書き出されるので、学習終了後にいつでも結果をみることができます。
さらに書き出されたデータはリアルタイムでブラウザ上のグラフに反映されます。
また、グラフは GUI 操作でダウンロードすることも可能です。
ファイルの書き出しやグラフのダウンロードのコードを書かなくてもいいのはほんとうに便利です。
私が感じた TensorBoard の利点をまとめると以下になります。
- 簡単にデータをグラフ表示可能
- グラフの保存が GUI で容易にできる
- データは外部ファイルに書き出されるので、結果の管理に使える
- 学習経過をリアルタイムに監視できる
- jupyter notebook からダッシュボードをひらける
他のものでも代替できるとは思うのですが、TensorBoard は学習コストが少なく手っ取り早く使えるのもいいです。
Pytorch で TensorBoard を使ってみる
上記のように便利な TensorBoard ですが、TensorBoard は TensorFlow じゃなきゃ使えないと思っていました。
しかしなんと Pytorch でも使えるんです!
私はディープラーニング系は Pytorch でずっと書いてきたので、Pytorch で使えるのはありがたいです。
それではさっそく Pytorch と TensorBoard が使える環境構築からやっていきます。
今回は Dcoker で環境構築を行います。
以下が今回使用したDockerfileです。
FROM nvcr.io/nvidia/pytorch:19.08-py3
RUN apt-get clean && apt-get update
RUN pip install msgpack==0.5.6
RUN pip install pillow tensorboard matplotlib tensorflow future torch torchvision --ignore-installed
RUN pip install wrapt==1.10.0 --ignore-installed
WORKDIR /workspace/work
CMD /bin/bash
(Dockerfile に慣れてないので微妙な書き方かもしれないです)
ちなみに Pytorch で TensorBoard を利用するのに必要なのは以下のバージョンになります。
- pytorch >= 1.1.0
- tensorboard >= 1.14
(参考:Using TensorBoard with PyTorch 1.1 or 1.2)
これをてきとうなフォルダに置いて、同じフォルダ内で以下のコマンドを実行します。
docker build -t tensorboard .これで今回の作業用 Docker image が作成されます。 イメージサイズが 10GB 近くなるので注意です。
イメージ作成後は以下のコマンドで、コンテナを起動します。
docker run --runtime=nvidia -it -v /path/to/dir:/workspace/work -p 8888:8888 -p 6006:6006 tensorboardちょっと長いんですが、やってることとしてはまず GPU が使えるように--runtime=nvidiaを指定します。
(※ nvidia-docker のインストールについては今回は触れません)
次に、-v /path/to/dir:/workspace/workでローカルの作業フォルダをコンテナ内にマウントします。
-p 8888:8888 -p 6006:6006は jupyter notebook と TensorBoard を動かすためのポートフォワードになります。
上記の docker run コマンドを実行するとコンテナ内に入れると思います。
それでは、簡単なコードで TensorBoard がどんなものか、どのように使えるか確認したいと思います。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# log出力用のディレクトリを指定
log_path = "./log"
# writerオブジェクト生成。パスを引数に指定しない場合は./runs/配下に出力される
writer = SummaryWriter(log_path)
x = np.array(range(1,10))
y = x * x
# xとyの値を記録していく
for i in range(len(x)):
writer.add_scalar("x", x[i], i)
writer.add_scalar("y", y[i], i)
# writerを閉じる
writer.close()Pytorch で TensorBoard を使うにはfrom torch.utils.tensorboard import SummaryWriter
をインポートします。
コードのやってることは単純で、iごとのxとyの値をそれぞれ別のグラフとして記録するというものです。
詳しい引数などは公式サイトを参照ください。
基本的にタグ、縦軸、横軸のように直感的な引数で簡単です。
上記コードを実行すると、log配下にevents.out.tfevents.1567930327.d6edca4d0003.82のようなファイルが生成されます。
それでは TensorBoard で出力を確認してみましょう。
なんと今回の環境だと以下のように jupyter notebook から TensorBoard をひらけます!
マジ便利です。
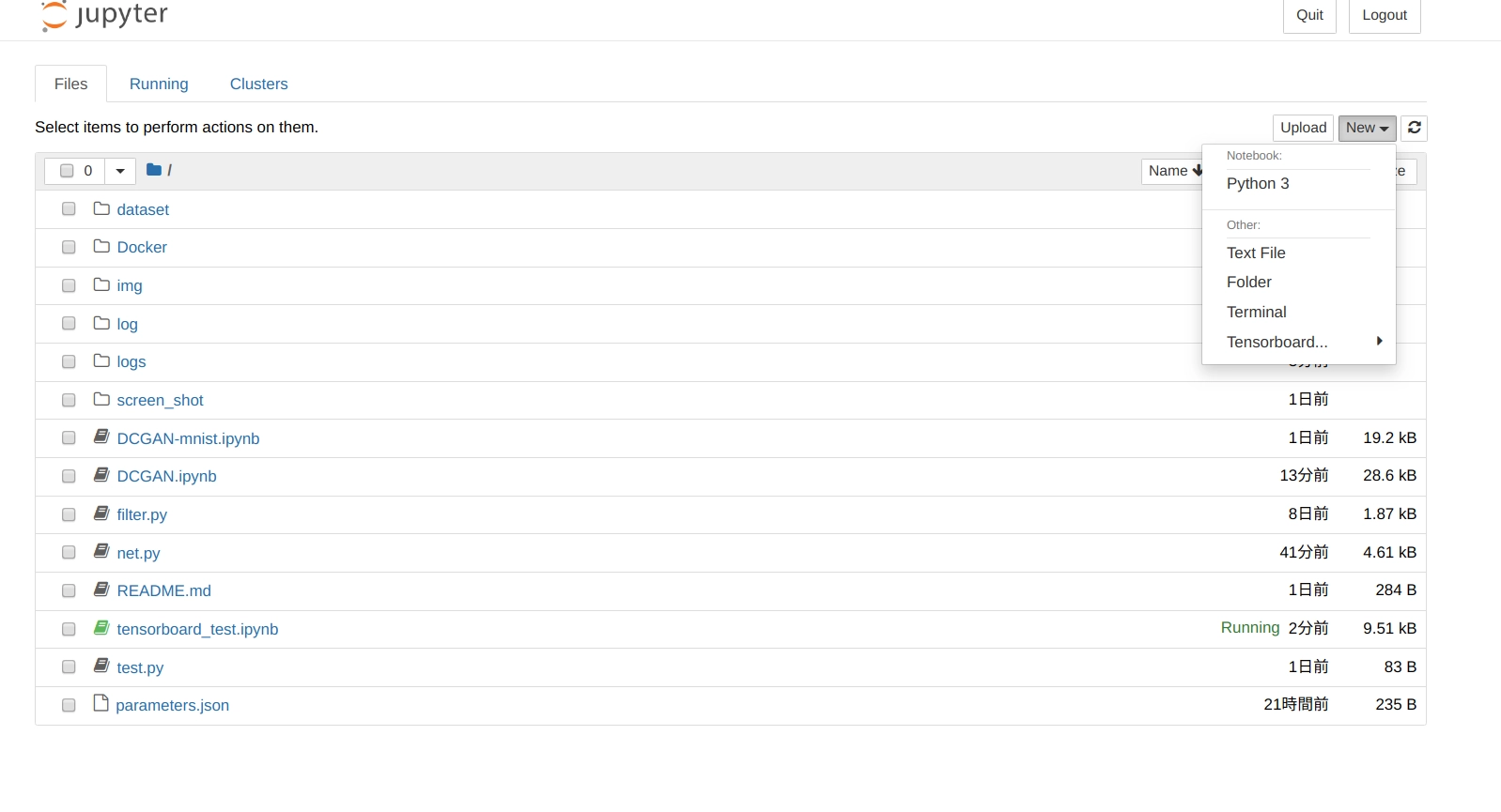
右上の New のプルダウンを押下すると、Tensorboard という項目があるのでクリックします。
Current か Custom ディレクトリの選択肢がでるので、今回は Custom を選択。
log 用のディレクトリを聞かれるのでパスを入力します。
今回はlogになるので以下の画像のように入力して ok を押します。
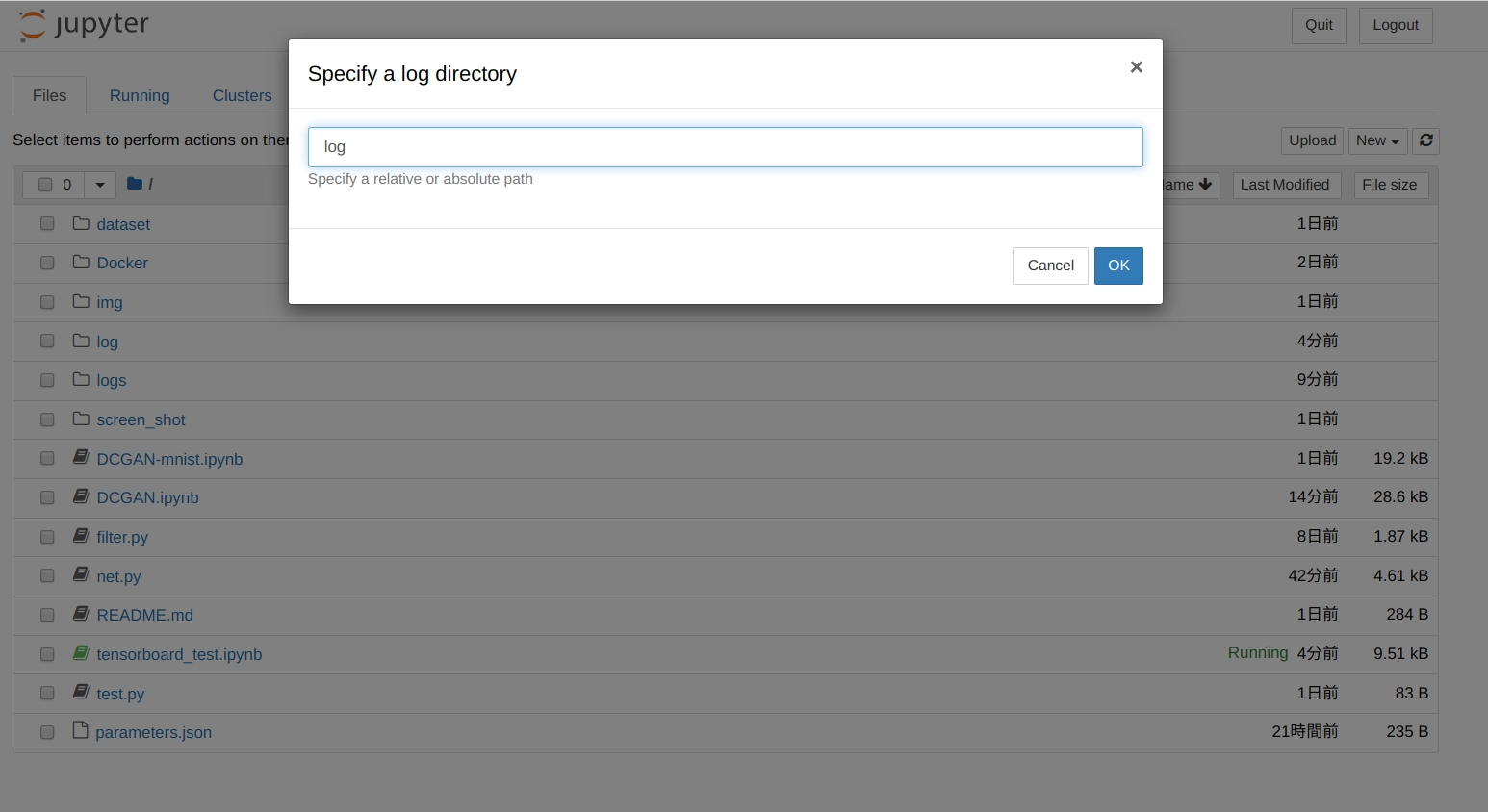
すると、別タブで以下のような TensorBoard のダッシュボードが表示されます。
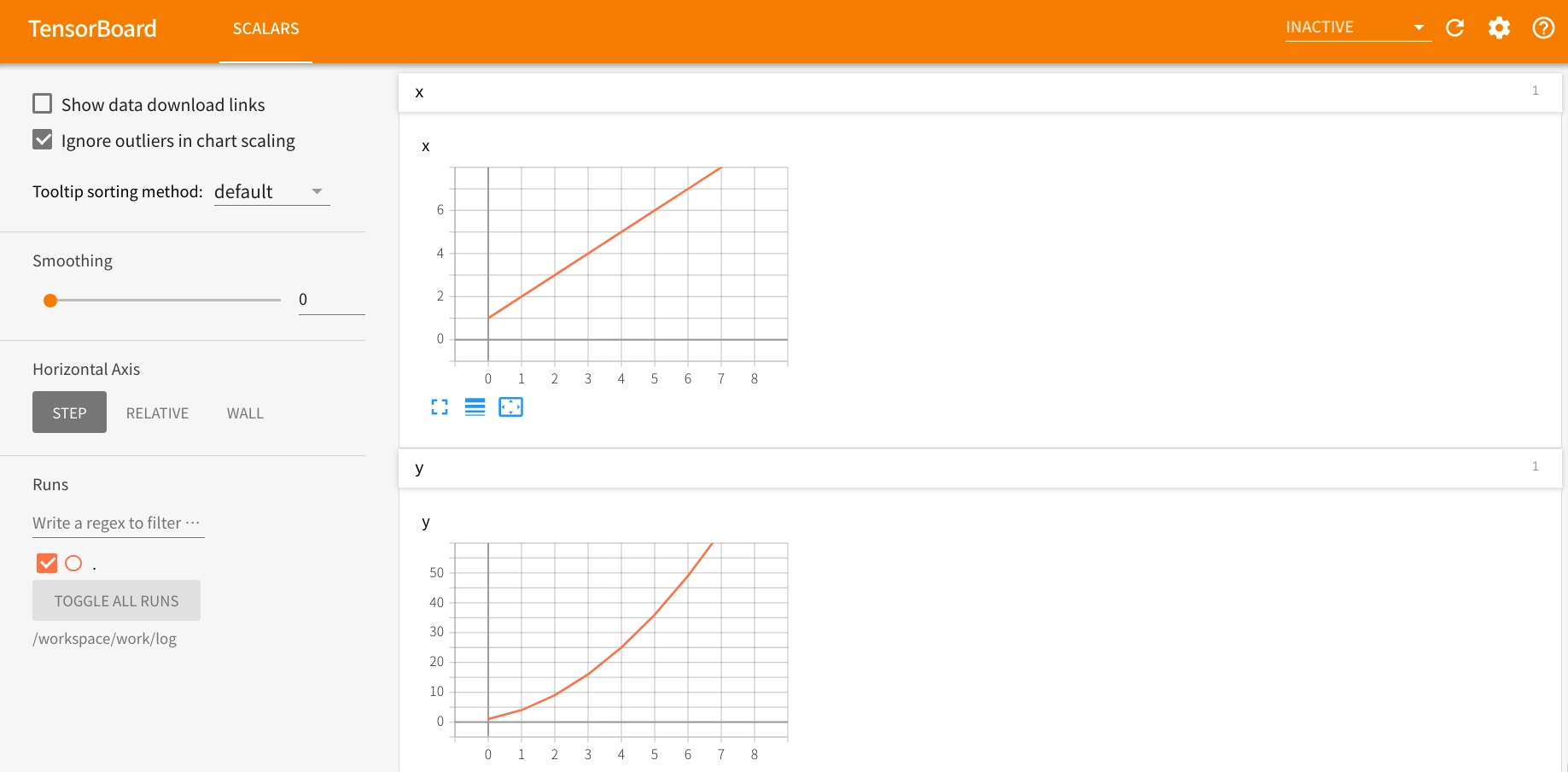
いい感じに表示されてます!
jupyter を介さずにターミナルから以下のコマンドでひらくこともできます。
あとから結果だけ確認したい場合に便利です。
tensorboard --logdir=log入力後、ブラウザでlocalhost:6006にアクセスすると以下のようにグラフが表示されます。
このように、TensorBoard を使うと簡単かつキレイにグラフを作成することができます。
TensorBoard で DCGAN の学習過程を可視化
さて、実際にディープラーニングで TensorBoard を使ってみましょう。
TensorBoard をディープラーニングで試してみる題材としてDCGANの Pytorch 実装を使います。
なぜ DCGAN かというと、GAN の特に古いものは学習が難しく、トライアンドエラーが必要になります。
loss の値を監視して学習の経過をみるのに TensorBoard が向いてると思ったからです。
DCGAN の Pytorch 実装は Pytorch の公式サイトにのっているので、そちらを参考に TensorBoard 部分を追記しました。
(参考:DCGAN TUTORIAL)
データは celebA を利用しました。
以下がコードになります。TensorBoard 用に変更した部分を抜粋しました。
それ以外は上記リンクの実装とほぼ同様なので省略してます。
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
# log用フォルダを毎回生成
now = datetime.now()
log_path = "./log/" + now.strftime("%Y%m%d-%H%M%S") + "/"
print(log_path)
img_list = []
G_losses = np.array([])
D_losses = np.array([])
iters = 0
# 学習のループ
for epoch in range(n_epoch):
for itr, data in enumerate(dataloader):
real_image = data[0].to(device) # 元画像
sample_size = real_image.size(0) # 画像枚数
noise = torch.randn(sample_size, nz, 1, 1, device=device) # 正規分布からノイズを生成
real_target = torch.full((sample_size,), 1., device=device)
fake_target = torch.full((sample_size,), 0., device=device)
# 識別器Dの更新
netD.zero_grad() # 勾配の初期化
output = netD(real_image) # 識別器Dで元画像に対する識別信号を出力
errD_real = criterion(output, real_target) # 元画像に対する識別信号の損失値
D_x = output.mean().item()
fake_image = netG(noise) # 生成器Gでノイズから贋作画像を生成
output = netD(fake_image.detach()) # 識別器Dで元画像に対する識別信号を出力
errD_fake = criterion(output, fake_target) # 贋作画像に対する識別信号の損失値
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake # 識別器Dの全体の損失
errD.backward() # 誤差逆伝播
optimizerD.step() # Dのパラメーターを更新
# 生成器Gの更新
netG.zero_grad() # 勾配の初期化
output = netD(fake_image) # 更新した識別器Dで改めて贋作画像に対する識別信号を出力
errG = criterion(output, real_target)
errG.backward() # 誤差逆伝播
D_G_z2 = output.mean().item()
optimizerG.step() # Gのパラメータを更新
if itr % display_interval == 0:
print('[{}/{}][{}/{}] Loss_D: {:.3f} Loss_G: {:.3f} D(x): {:.3f} D(G(z)): {:.3f}/{:.3f}'
.format(epoch + 1, n_epoch,
itr + 1, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
if epoch == 0 and itr == 0: # 初回に元画像を保存する
vutils.save_image(real_image, '{}/real_samples.png'.format(outf),
normalize=True, nrow=10)
# Save Losses for plotting later
G_losses = np.append(G_losses,errG.item())
D_losses = np.append(D_losses,errD.item())
# Tensorboard用のデータ
writer.add_scalar("G_loss",errG.item(),iters)
writer.add_scalar("D_loss",errD.item(),iters)
iters += 1
if epoch % 10 == 0:
fake_image = netG(fixed_noise)
writer.add_image("fake_image",vutils.make_grid(fake_image), epoch)
# モデルの保存
if (epoch + 1) % 50 == 0: # 50エポックごとにモデルを保存する
torch.save(netG.state_dict(), '{}/netG_epoch_{}.pth'.format(outf, epoch + 1))
torch.save(netD.state_dict(), '{}/netD_epoch_{}.pth'.format(outf, epoch + 1))
writer.close()500 エポック回した結果が以下になります。
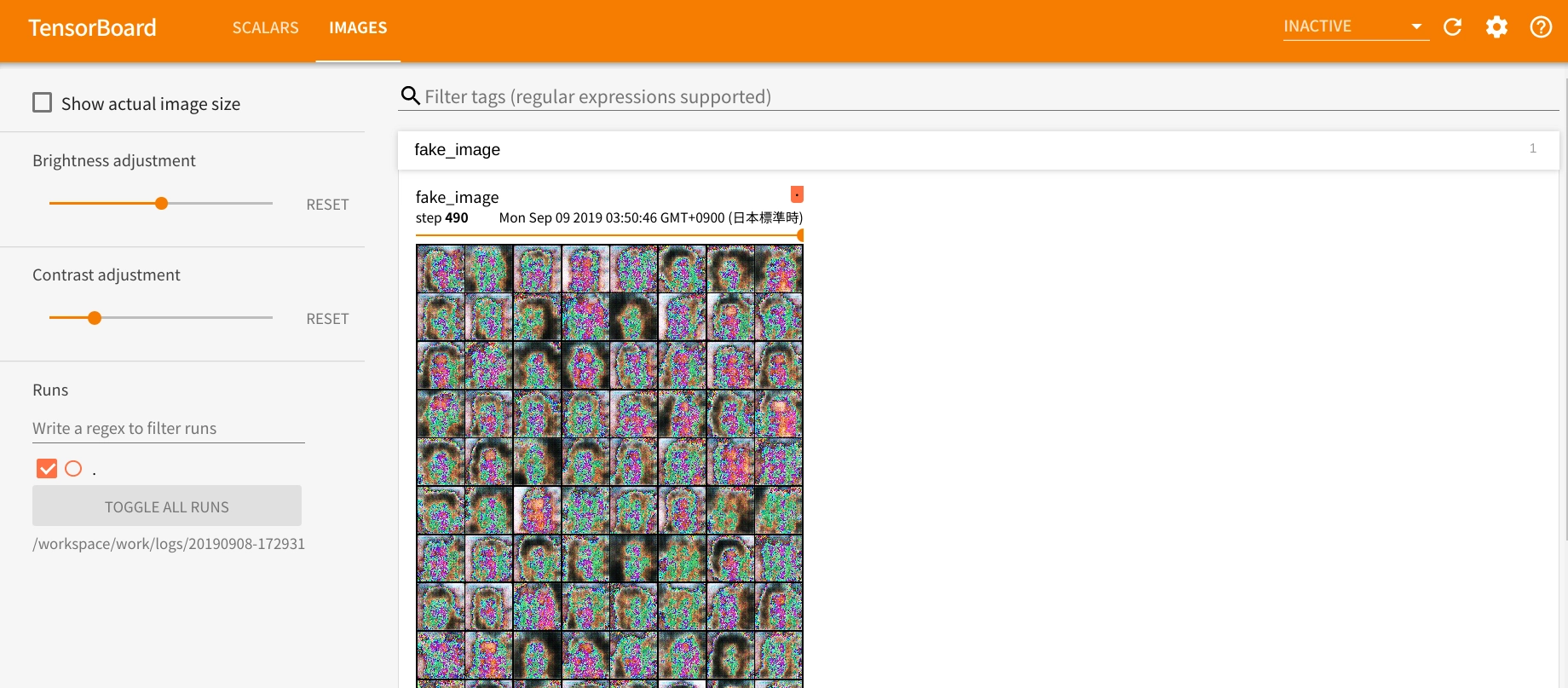
うーんな画像が生成されてます。
もうちょっと回せばいいのがでそうかなという感じです。
微妙な結果になった原因はおそらく画像枚数を 1000 枚で学習させたからだと思います。
マシンスペック的に celeba の画像全部は無理でした。
他のパラメータは特に変えてないです。
以下は生成器と識別器のロスになります。
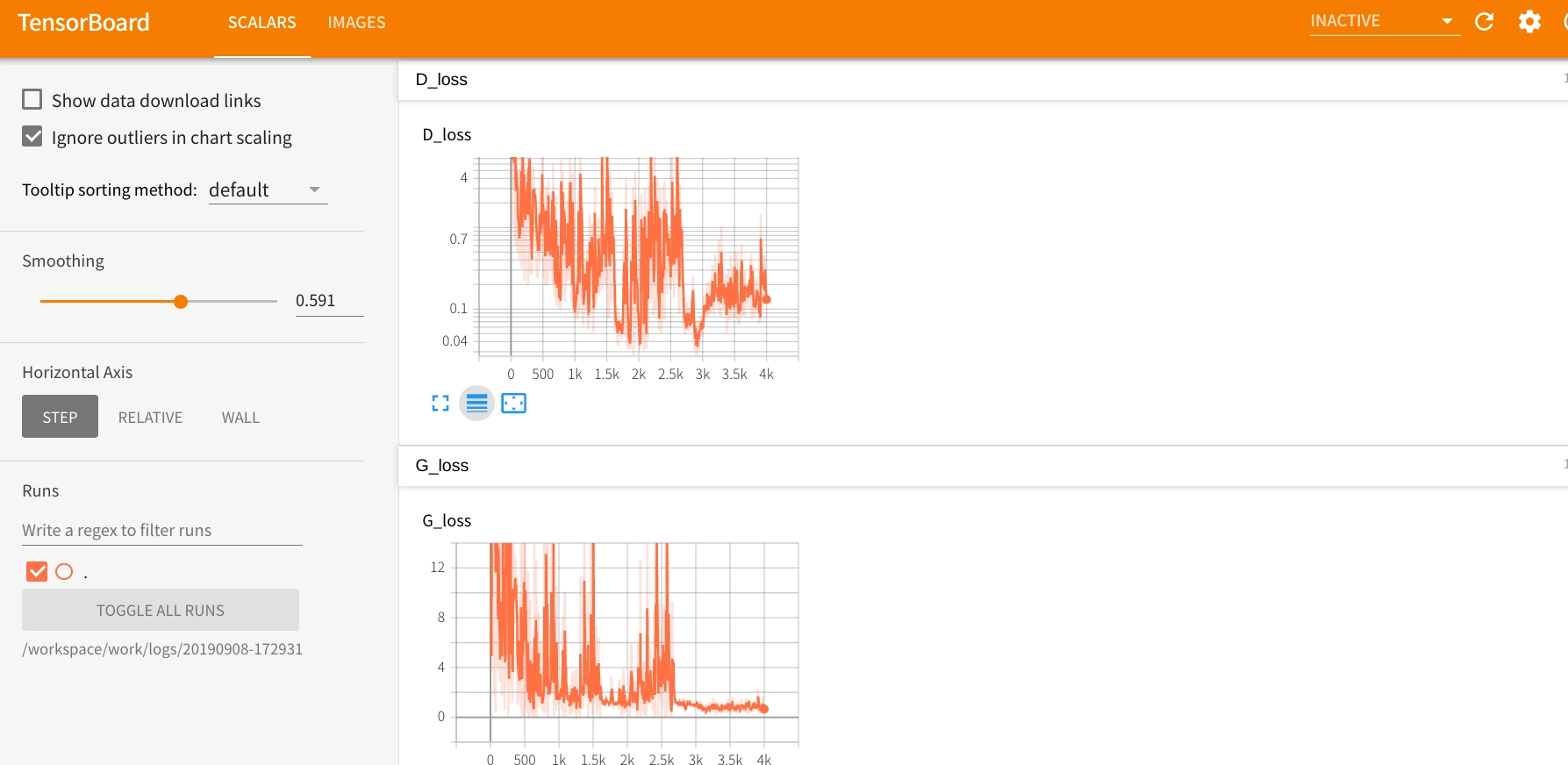
学習は順調に進んでるように見えます。
検証結果の紹介は以上です!
ハマったところ 1
まずは環境構築の部分で以下のエラーに悩みました。
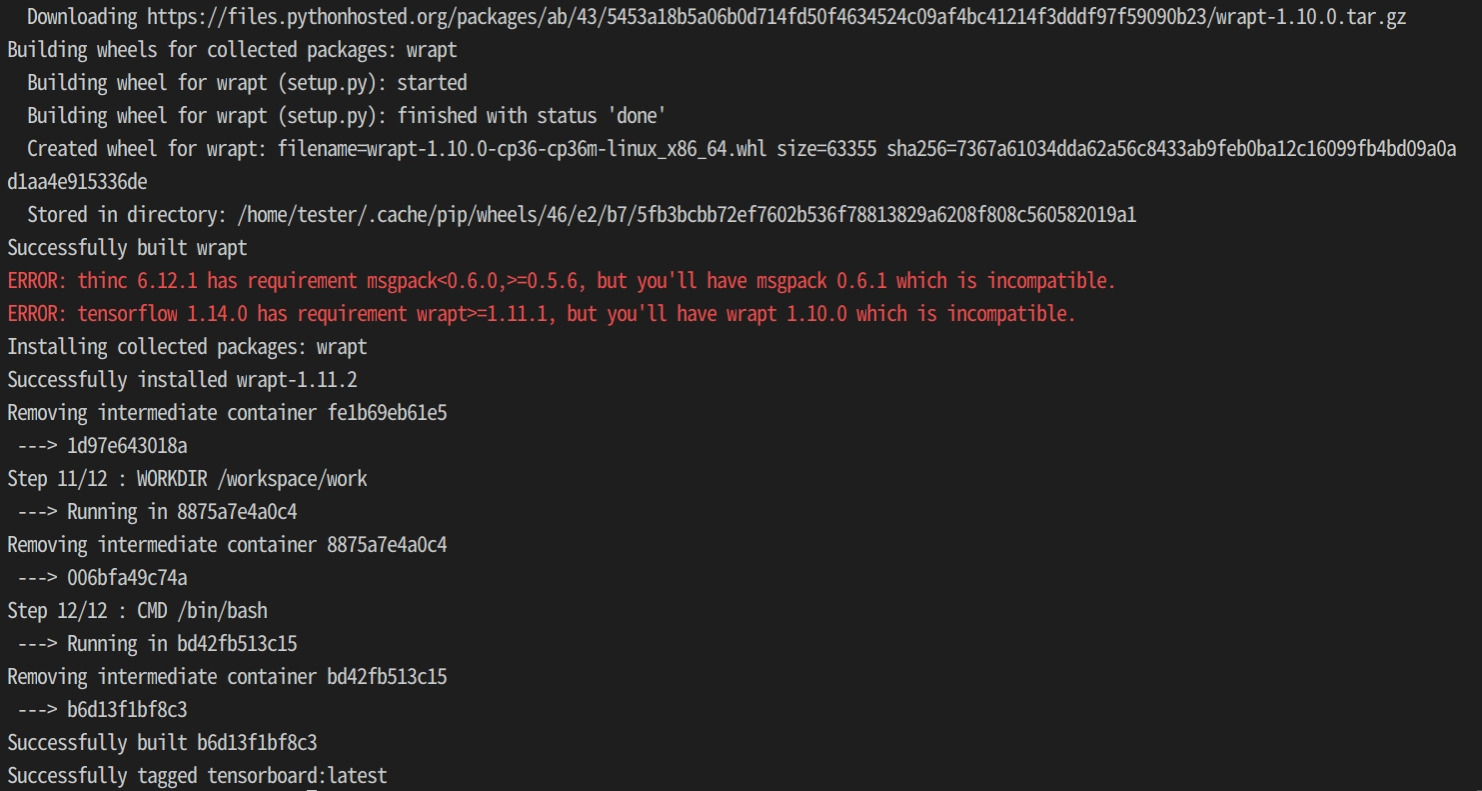
このthincというやつのエラーがどうやっても回避できなかったです。
結局、このエラーを放置しても作業に支障はなかったのですが、なんかモヤっとします。
今後、対策をちゃんと調べようと思います。
ハマったところ 2
次に、作業は jupyter notebook で行っていたのですが、TensorBoard がリセットされない問題が発生しました。
どういう現象かというと、お試しで作成したデータを削除して、
新しく生成されたデータのみを TensorBoard で可視化しようとしたところ、
古いデータがグラフに残ったまま次のデータが同一のグラフに描画されてしまいました。
元の tfevent ファイルを削除してもどうにもならなかったです。
とりあえずグラフが重なってしまうのは評価の上で論外だったので、一応対策しました。 対策は 3 つほど見つけました。
- tfevent は常に新しいディレクトリに保存する
- 可視化部分を含むコードを変更した場合は、jupyter notebook の kernel から
Restart & Clear Outputを行う tf.reset_default_graph()を使う
手っ取り早く確実に効果があるのは一つ目です。
TensorBoard は log ディレクトリに指定した配下ではディレクトリごとに表示を分けることができます。
なので、実行のたびに新しくディレクトリを作成し、tfevent ファイルはその下に保存されるようにすると、グラフが重なることなく表示できます。
2 と 3 番目は試したのですが、効果がみられなかったです。(使い方が違った可能性あり)
感想
TensorBoard 便利すぎて感動です。
導入、学習コストも低く、でてくる出力の見た目も申し分ないです。
またリアルタイム可視化も便利でした。
リアルタイムに生成画像やロスを見れるので GAN の学習にぴったりでした。
jupyter notebook から直接開けるのも使いやすくてポイント高いです。