【学び直し】Pytorchの基本とMLPでMNISTの分類・可視化の実装まで
本記事では Pytorch を1から学び直します。
しばらく触っていなかったらすっかり忘れてしまって困ったのでしっかりまとめていきます。
進め方はまず公式チュートリアルを行い、理解したことを書いていきます。
実行環境は Google Colaboratory です。
Pytorch 基礎
まず、Pytorch の基本になるtensorについてです。
tensorとは、numpy の ndarray のようなもの。ようは、任意の次元の配列を作成できるものです。
以下が例になります。
import torch
# 初期化されていない5☓3行列
x = torch.empty(5,3)
# >> tensor([[2.2037e-35, 0.0000e+00, 3.3631e-44],
# [0.0000e+00, nan, 0.0000e+00],
# [1.1578e+27, 1.1362e+30, 7.1547e+22],
# [4.5828e+30, 1.2121e+04, 7.1846e+22],
# [9.2198e-39, 7.0374e+22, 0.0000e+00]])
print(x.shape)
# >> torch.Size([5, 3])
print(x[0])
# >> tensor([2.2037e-35, 0.0000e+00, 3.3631e-44])
print(x[0][0])
# >> tensor(1.6076e-35)さらにイメージをつかむために手計算したものと tensor で計算したものを突き合わせてみます。 計算するのは以下の行列。
$$ \left \begin{array}{rr} 1 & 1 \ 1 & 1 \ \end{array} \right \left \begin{array}{rr} 1 & 0 \ 0 & 1 \ \end{array} \right = \left \begin{array}{rr} 1 & 1 \ 1 & 1 \ \end{array} \right $$
これを tensor で計算するには以下のようにします。
x1 = torch.tensor([[1,1],[1,1]])
x2 = torch.tensor([[1,0],[0,1]])
# 通常の掛け算はそれぞれの位置と同じ場所をかけた値になる
y = x1 * x2
print(y)
# >> tensor([[1, 0],
# [0, 1]])
# torch.mmで行列同士の積が計算できる
y = torch.mm(x1, x2)
print(y)
# >> tensor([[1, 1],
# [1, 1]])ちゃんと計算できていることがわかります。
よく使う tensor データ操作方法
ここではよく使う tensor データ操作方法を紹介します。numpy に似ているものが多いので numpy 慣れしていれば余裕です。
tensor.empty()- 空の tensor を生成
tensor.rand()- 乱数で初期化された tensor を生成
tensor.zeros()- ゼロで初期化された tensor を生成
tensor.ones- 1 で初期化された tensor を生成
tensor.randn_like()- 引数に与えられた tensor と同じサイズの tensor を生成
torch.arange()- 連続した tensor を生成
torch.view()- tensor のサイズを変更する
torch.squeeze()- 次元を減らす
torch.unsqueeze()- 次元を増やす
torch.detach- グラフから切り離す(勾配の追跡を止める)
- 自分も完全に理解したかあやしいが、誤差を伝搬させたくない場合に使う
viewとsqueezeはわかりづらいので実際に試します。
まずはviewから。viewはよく見るのでしっかりやります。
x = torch.rand(2,2)
# >> torch.Size([2, 2])
print(x.size())
y = x.view(4)
# >> torch.Size([4])
print(y.size())
z = y.view(-1, 2)
# >> torch.Size([2, 2])
print(z.size())
xx = x.view(-1, 1, 1)
# >> torch.Size([4, 1, 1])
print(xx.size())viewでは引数にマイナス1を入れると、そこの次元数を自動で計算してくれます。したがって、最後の例ではサイズが 2☓2 から 4☓1☓1 に変わってます。
次はsqueezeです。以下に例をのせました。
# てきとうなtensorを定義
x = torch.empty(1,5,1,3)
# >> torch.Size([1, 5, 1, 3])
print(x.shape)
# 次元削除
x = x.squeeze()
# >> torch.Size([5, 3])
print(x.shape)
# 次元を増やす。引数の位置に増える
x = torch.unsqueeze(x,0)
# >> torch.Size([1, 5, 3])
print(x.shape)このようにsqueezeでは計算上なくても問題ない tensor の形状が1となる部分を消して次元を下げてくれます(次元という言葉は適切なのか?)。
逆にunsqueezeは引数の位置に次元を増やしてくれます。
自動微分機能
機械学習では勾配を計算するのに微分が必要になります。tensor ではデフォルトで勾配情報を保持する仕組みがあります。
今回も簡単な数式をたてて検証します。
$$ y = x * w + b $$
やることは偏微分です。
x = torch.tensor(1, requires_grad=True, dtype=torch.float32)
w = torch.tensor(2, requires_grad=True, dtype=torch.float32)
b = torch.tensor(3, requires_grad=True, dtype=torch.float32)
print(x)
print(w)
print(b)
y = x * w + b
print(y)
# 微分
print(y.backward())
# 微分結果
print(x.grad)
print(w.grad)
print(b.grad)
# Output
# tensor(1., requires_grad=True)
# tensor(2., requires_grad=True)
# tensor(3., requires_grad=True)
# tensor(5., grad_fn=<AddBackward0>)
# None
# tensor(2.)
# tensor(1.)
# tensor(1.)requires_grad=Trueとすることで微分の計算対象であると定義できます。
requires_grad=Trueされた tensor で関数を作成する(上記y)と計算グラフと呼ばれるものが出来上がります。
この計算グラフをbackward()することでrequires_grad=Trueとなっている変数の勾配が算出されます。
結果は x で微分した場合、w で微分した場合とそれぞれ合ってます。
Pytorch での機械学習の流れ
ここからは Pytorch を使った機械学習の流れを追っていきます。基本は以下のようになると思います。
- dataset
- dataloader
- network
- 損失関数
- optimaizer
- epoch 繰り返し(学習)
- 順伝搬
- loss, acculacy 計算
- backward
- 重み更新
これを順番に書くと以下のようになります。今回はわかりやすさ重視し、ネットワークは MLP で MNIST の分類を行います。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import datasets, transforms
from datetime import datetime
# colabでgoogle driveをマウントしてない場合のパス
root="content/"
# dataの変換方法を定義
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# dataをダウンロード
train_set = datasets.MNIST(root=root, train=True, transform=trans, download=True)
test_set = datasets.MNIST(root=root, train=False, transform=trans, download=True)
# cpuかgpuか
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# dataloaderを定義
train_loader = DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = DataLoader(test_set, batch_size=100, shuffle=False)
# Networkを定義
class MLPNet (nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(1 * 28 * 28, 512)
self.fc2 =nn.Linear(512, 512)
self.fc3 = nn.Linear(512, 10)
self.dropout1=nn.Dropout2d(0.2)
self.dropout2=nn.Dropout2d(0.2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = self.dropout2(x)
return F.relu(self.fc3(x))
net = MLPNet().to(device)
# loss関数
criterion = nn.CrossEntropyLoss()
# 最適化方法
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
# log用フォルダを毎回生成
# tensorboardの可視化用
now = datetime.now()
log_path = "./runs/" + now.strftime("%Y%m%d-%H%M%S") + "/"
print(log_path)
# tensorboard用のwriter
writer = SummaryWriter(log_path)
epochs = 30
for epoch in range(epochs):
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
# train dataで訓練
net.train()
for i, (images, labels) in enumerate(train_loader):
images, labels = images.view(-1, 28*28*1).to(device), labels.to(device)
# 勾配を0にリセット
optimizer.zero_grad()
# 順伝搬
out = net(images)
# loss計算
loss = criterion(out, labels)
# 計算したlossとaccの値を入れる
train_loss += loss.item()
train_acc += (out.max(1)[1] == labels).sum().item()
# 誤差逆伝搬
loss.backward()
# 重みの更新
optimizer.step()
# 平均のlossとacc計算
avg_train_loss = train_loss / len(train_loader.dataset)
avg_train_acc = train_acc / len(train_loader.dataset)
# validation dataで評価
net.eval()
with torch.no_grad():
for (images, labels) in test_loader:
images, labels = images.view(-1, 28*28*1).to(device), labels.to(device)
out = net(images)
loss = criterion(out, labels)
val_loss += loss.item()
acc = (out.max(1)[1] == labels).sum()
val_acc += acc.item()
avg_val_loss = val_loss / len(test_loader.dataset)
avg_val_acc = val_acc / len(test_loader.dataset)
# print log
print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}'
.format(epoch+1, epochs, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc))
# tensorboard用
writer.add_scalars('loss', {'train_loss':avg_train_loss, 'val_loss':avg_val_loss},epoch+1)
writer.add_scalars('accuracy', {'train_acc':avg_train_acc, 'val_acc':avg_val_acc}, epoch+1)
writer.close()かなり基本的なコードになっています。tensorboard を使わずに matplotlib で可視化しても大丈夫です。tensorboard の使い方については以降で説明します。
Google Colabratory で PyTorch の TensorBoard を使う方法
以前、jupyter notebook で pytorch から tensorboard を使う方法を紹介しました。
なんと Google Colabratory でも pytorch で tensorboard が使えました!
上述のコードも tensorboard での可視化を前提に書いてあるので参考にしてください。
使い方は以下のように簡単です。
- Google Colabratory の任意のディレクトリに writer で結果を保存
- セルに
%load_ext tensorboardと%tensorboard --logdir ./runs/<dir name>/を入力し、実行
これをセルに入れて実行すれば OK です。
# 2回目以降の実行時はloadではなく、以下のreloadを使う
%load_ext tensorboard
# %reload_ext tensorboard
%tensorboard --logdir ./runs/<dir name>/コメントに書いたように%load_ext tensorboardを2回実行すると異なるポートで実行されて結果が見えなくなったので、2回目以降の実行は%reload_ext tensorboardを使うようにします。
また、logdirは変数ではダメだったので上記のように文字列で直接パスを書きました。
先ほどのコードの次のセルで tensorboard の可視化を行った結果が以下の画像になります。
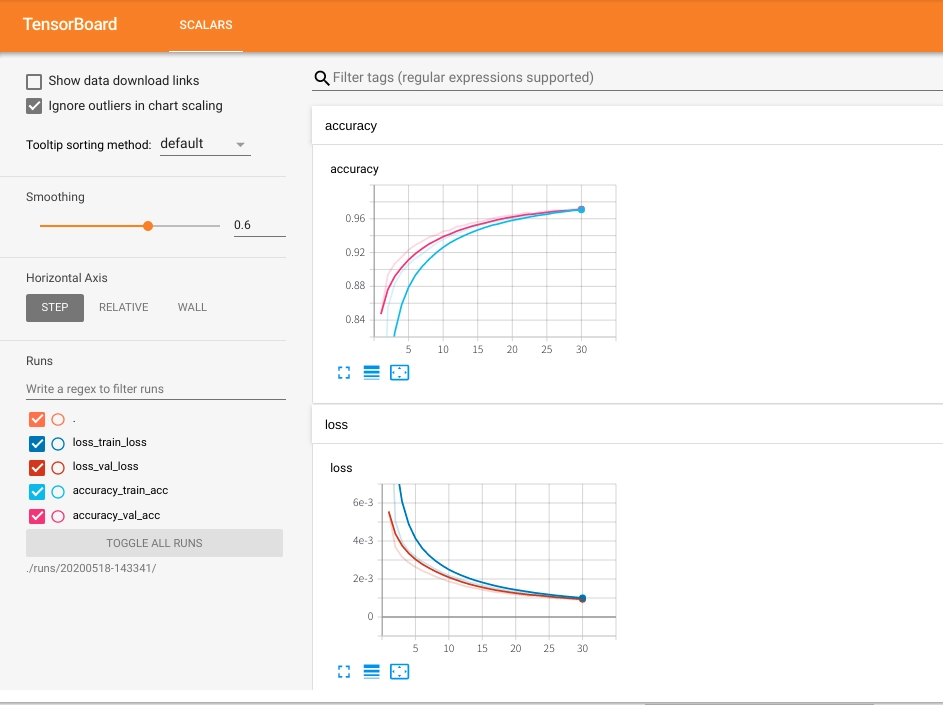
以前 jupyter で紹介したときとは異なり、新規タブではなくセルの中に上記のような TensorBoard が現れます。
めちゃめちゃ見やすくできてます!