自然言語処理再入門:TfIdfと次元圧縮手法で文章を可視化
世の中 Transformer 系のアルゴリズムが主流になっているところで、あえての TfIdf を復習したいと思います。
使用するデータセットは livedoor です。
データ探索
まずは使用するデータがどのようなものか見てみます。データを見るのは大事です。
| 項目 | 値 |
|---|---|
| データ数 | 5893 |
| ラベル数 | 9 |
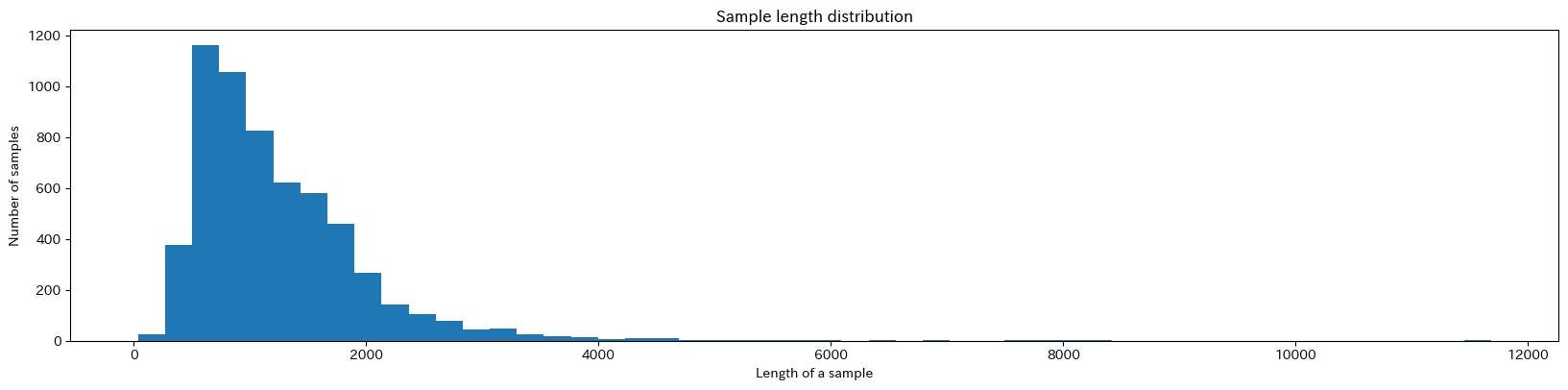
続いて、各文書の長さの分布です。今回は大体 1,000 文字くらいの文書が多いようです。ラベルごとの文書数に若干偏りがありますが、今回は精度をあまり見ないので省略します。
前処理
BERT 系と異なり、TfIdf では文書の前処理は重要です。
TfIdf で作成されるベクトルでは文書内の単語の出現回数が重要となってきます。
そのため、なるべく同じ意味の単語を統一したり、不要な単語を削除しておくことが大事になります。
前処理で実施する内容は以下の通り。
- 改行除去
- 正規化
- 大文字・小文字変換
- URL 除去
- 不要記号除去
- 数字を 0 に
こちらがコードです。
from typing import List
import re
import neologdn
def clean_text(texts:List[str])->List[str]:
cleaned_text = []
for text in texts:
#改行削除
text = text.replace("\n", "")
# URL削除
pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+"
text = re.sub(pattern, ' ', text)
# 不要記号削除
pattern = '[!"#$%&\'\\\\()*+,-./:;<=>?@[\\]^_`{|}~「」〔〕“”◇ᴗ■☆●↓→♪★⊂⊃※△□◎:〈〉『』【】&*・()$#@、?!`+¥%]'
text = re.sub(pattern, ' ', text)
text = neologdn.normalize(text)
# 大文字・小文字変換
text = text.lower()
# 数字を0に
text = re.sub(r'\d+', '0', text)
cleaned_text.append(text)
return cleaned_text方針はなるべく単語の多様性を減らし、不要な単語は消すです。ストップワード除去は一旦結果を見てから考えます。
上記前処理を行い、単語のわかち書きにします。形態素解析は ginza を使用しました。 わかち書きしたリストを使用し、単語の分布を表示しました。
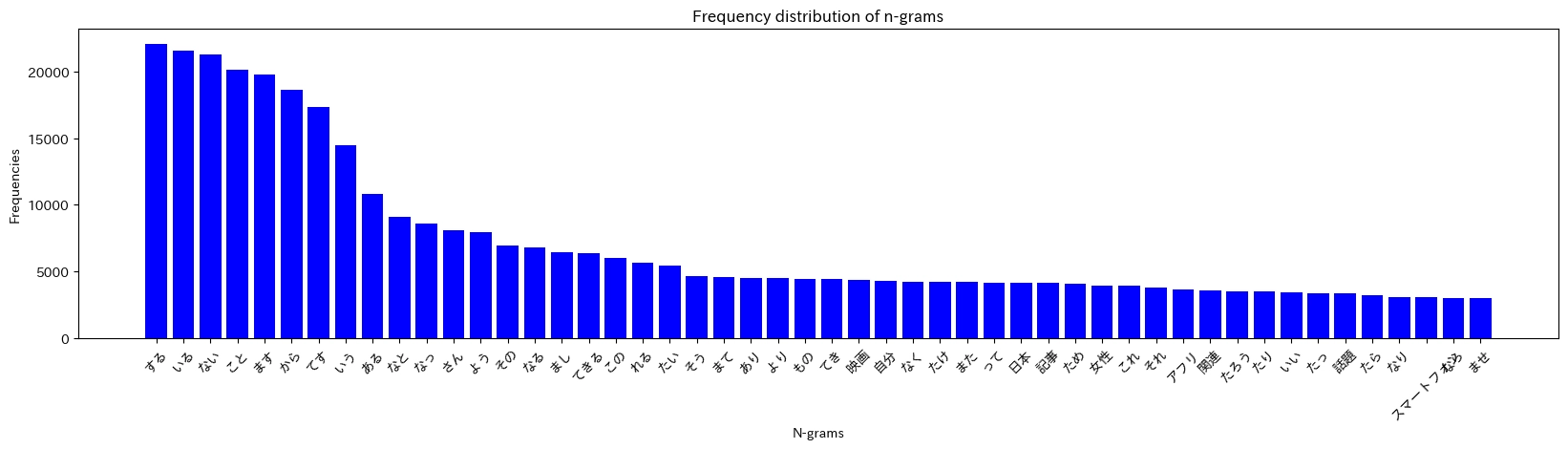
日本語で一般的な単語が多いことがわかります。また、「する」「いる」など頻出する単語があることもわかります。
TfIdf で文書をベクトル化
ようやく TfIdf です。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_df=0.95, min_df=10)
X = vectorizer.fit_transform(tokenised_texts)
# X.shape >> (5893, 12267)max_df や min_df は何度か試して vocabulary*を確認し、決めました。
次元圧縮手法で可視化
次元圧縮手法はいくつかありますが、今回は t-sne と umap を試しました。
最終的には umap が一番よく分離できていました。また、計算時間的にも umap が使いやすいです。
以下が umap のコードと結果です。
from sklearn.manifold import TSNE
import umap
#t-sneの場合
#x_embedded = TSNE(n_components=2, learning_rate='auto',init='pca', perplexity=3)
# umap
mapper = umap.UMAP(random_state=0)
umap_vecs = mapper.fit_transform(X)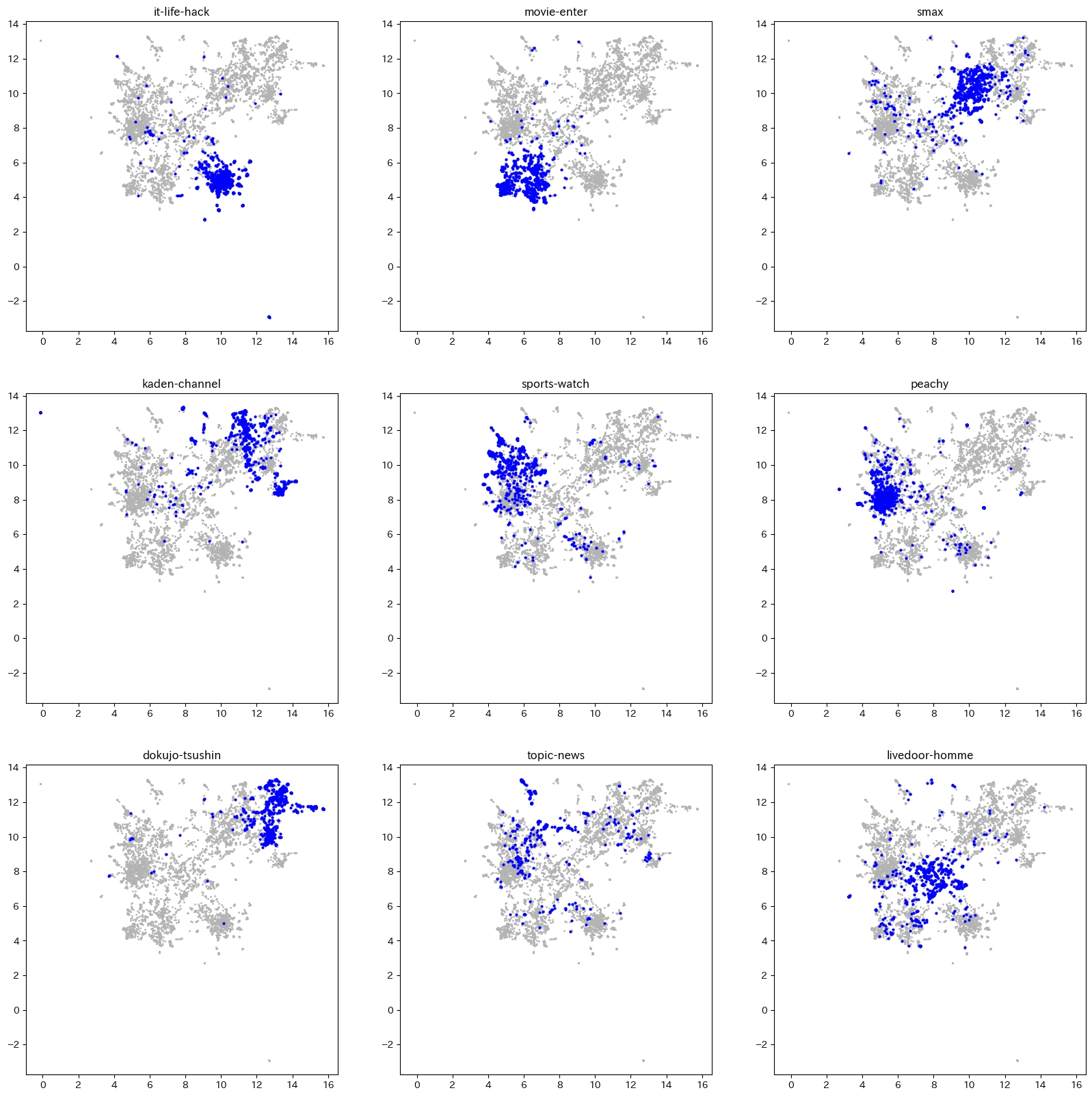
こちらが t-sne です。perplexity の値が難しいです。
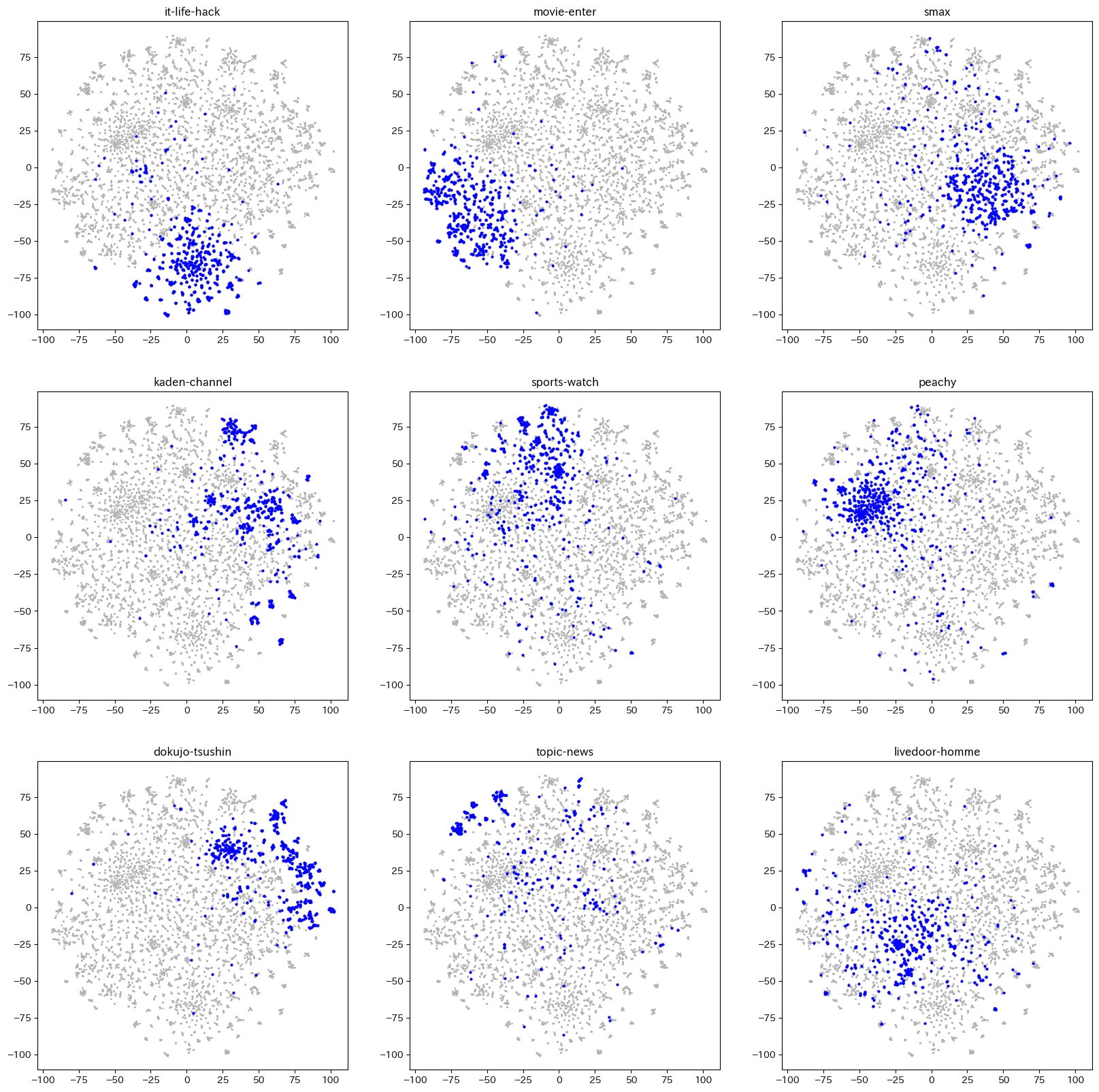
以下参考までに可視化用のコードです。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# category_listはlivedoorのラベルです。
fig = plt.figure(figsize=(20,20))
labels = np.array(list(df.label))
for label in range(len(category_list)):
plt.subplot(3,3,label+1)
plt.title(f"{category_list[label]}")
index = labels==label
plt.plot(
tsne_vecs[:, 0],
tsne_vecs[:, 1],
# umap_vecs[:, 0],
# umap_vecs[:, 1],
'o',
markersize=1,
color=[0.7,0.7,0.7]
)
plt.plot(
tsne_vecs[index, 0],
tsne_vecs[index, 1],
# umap_vecs[index, 0],
# umap_vecs[index, 1],
'o',
markersize=2,
color ='b'
)まとめ
livedoor データは文書分類で頻出のデータセットですが、結果を見るにいい感じに分類できそうな感じがします。