EC2でDeep Learning AMIを使う方法
以前の EC2 の記事の中身がうすかったのでリライトします。
EC2 の使いかたはすでにいろいろ情報があるので、有料の Deep Learning 用 AMI を試してみようと思います。
Deep Learning 用 AMI について
簡単にいうと、EC2 で GPU や機械学習でよく使うものがすぐに利用できるというものです。
参考:AWS 深層学習 AMI
機械学習では、環境構築が意外と大変で、新しく始める人やちょっと試したい人にとってはめんどうな作業です。
AWS の深層学習用 AMI では、そういった作業を行わずに、すぐに開発を始めることができるのが利点です。
ただし、有料になるので利用する際は料金にだけは気をつけてください。
料金 !!
料金だけはぜっっっったいに確認しといてください。
GPU 搭載のインスタンスは料金が高いのでよく確認することをおすすめします。
いくつか料金例をだしておきます。
| インスタンス名 | GPU 種類 | GPU 数 | GPU メモリ (GiB) | 料金 |
|---|---|---|---|---|
| p2.xlarge | Tesla K80 | 1 | 12 | 0.900 USD |
| p2.8xlarge | Tesla K80 | 8 | 96 | 7.200 USD |
| p3.2xlarge | Tesla V100 | 1 | 16 | 3.06 USD |
| p3.8xlarge | Tesla V100 | 4 | 64 | 12.24 USD |
参考:Amazon EC2 P2 インスタンス 、Amazon EC2 P3 インスタンス
p2.xlarge であればギリ使ってもいいかなという料金ですね。 1 時間 3 ドルくらいになるとドキドキして開発に集中できなそうです笑
SageMaker との使い分け
AWS って機械学習開発者用のサービスとして SageMaker 出してるよね? SageMaker でいいのでは?
という方向けに SageMaker との使い分けについて書いていきます。
まず、SageMaker を利用する場合は、SageMaker 用のコードを書かないといけないです。
トレーニングデータの読み込みやトレーニングの開始に SageMaker 用の書き方があるので、その書き方を覚えないといけないです。
また、SageMaker で提供されていないアルゴリズムを利用する場合は、さらに Docker 等についても覚えないといけないです。
したがって、普段はローカルのマシンで開発していて、マシンスペックが足りないからクラウド使おうという場合には、SageMaker だとすぐにトレーニングを開始できないため不便です。
一方で、EC2 の深層学習用 AMI だと普段の開発環境とほぼ同じように扱えるので、新しく覚えたりすることが少なく簡単です。
SageMaker は、SageMaker で開発を完結させるなら全然ありです。
トレーニング中の出力は CloudWatch に流れるし、ハイパーパラメータなどもトレーニングごとに記録してくれるので便利です。
Google Colaboratory でよくない?
ほとんどの場合、Google Colaboratory で十分です!
Google Colaboratory は無料で GPU と TPU が使えて、機械学習に必要なものがある程度インストールされているので、ちょっとした開発なら一番いい選択肢だと思います。
ただし、Google Colaboratory は利用時間が同じセッションにつき Max で 12 時間くらいまでなので、GPU で長時間学習する場合にはむかないかもです。
また、Google Drive のマウントを行う場合は、SageMaker ほどではないですが、多少 Google Colaboratory によせた書き方が必要になります。
EC2 で Deep Learning AMI を使う方法
実際に EC2 で Deep Learning AMI を試してみます。
インスタンスタイプの選択とセキュリティグループ以外は、普通の EC2 の起動と同じになります。
ところどころスクショを端折ってるので詳しく知りたい方は、下記の公式ブログも参考にどうぞ。
参考:Get Started with Deep Learning Using the AWS Deep Learning AMI
それでは、試していきましょう。
まずはコンソールにログインして、サービスから EC2 を選択します。
その後、インスタンスの作成を選択します。
すると、AMI を選択する画面になるので、検索でdeep learningと入力すると、以下のような画面になるので、一番上の**Deep Learning AMI (Ubuntu 16.04)**を選択します。
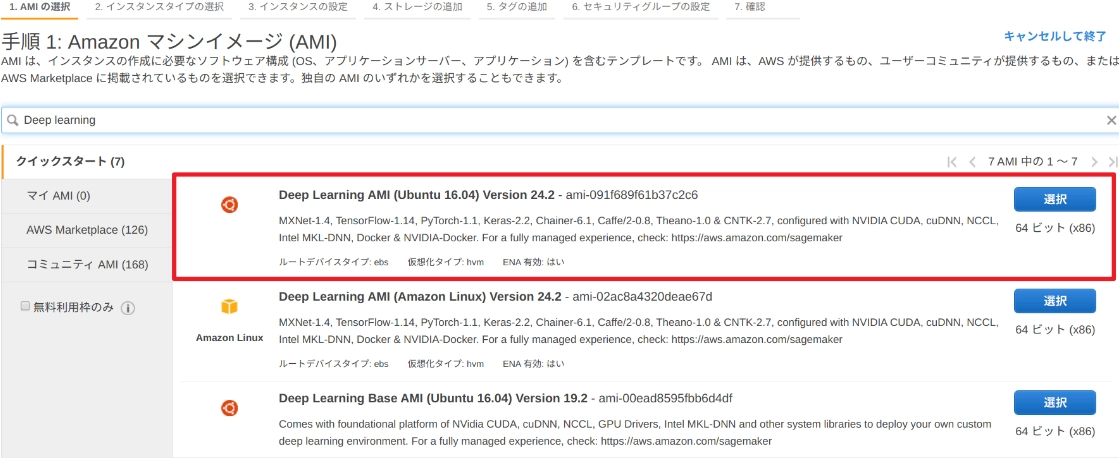
次はインスタンスタイプの選択です。
どれを選んでもいいのですが、ここでは GPU が使えるp2.xlargeを選択します。
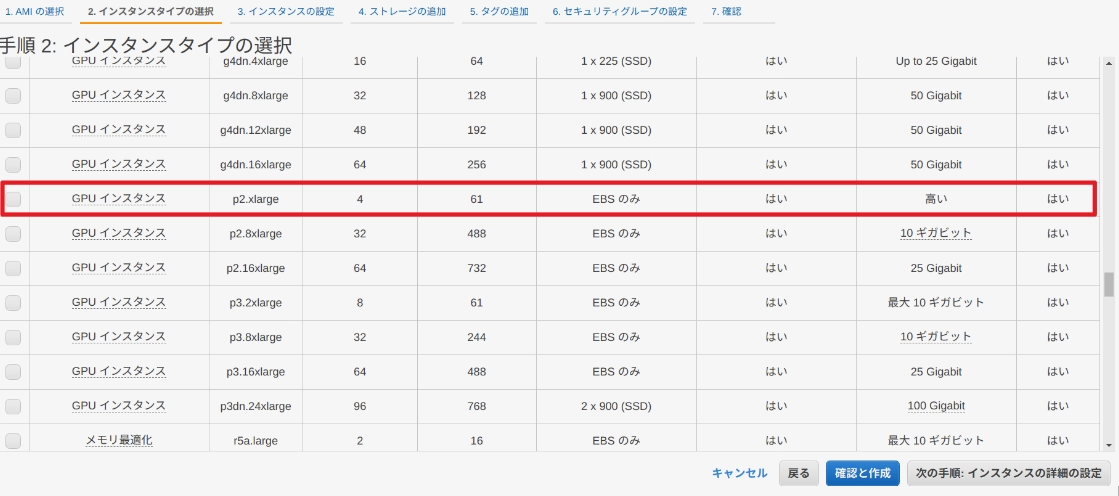
次の手順 3、4、5 はそのままで手順 6 のセキュリティグループだけ少しいじります。
以下のように ssh 用と、タイプをカスタム TCPにして jupyter、tensorboard 用のポートとして8888と6006を開けておきます。
ソースのところは自宅の IP などに限定しておくと安全です。
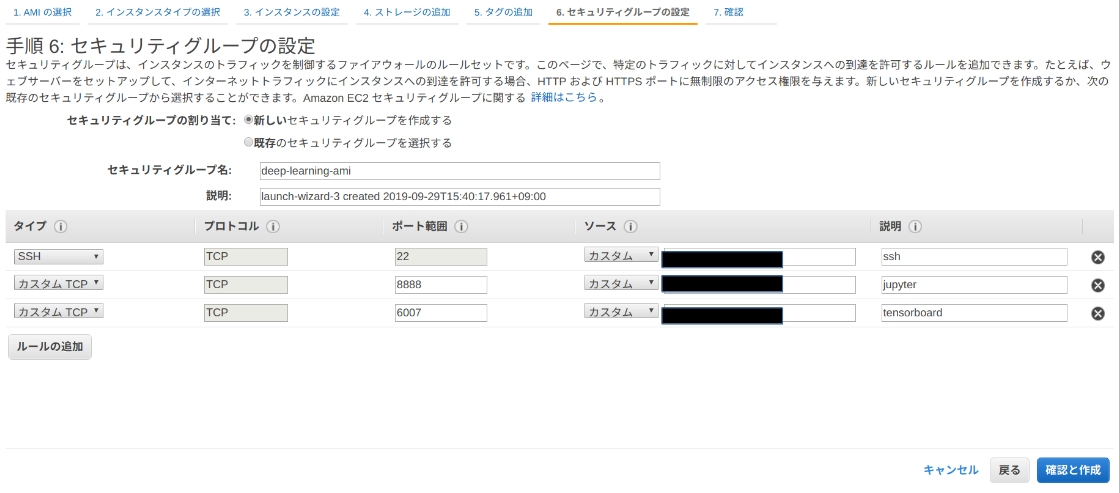
あとは確認画面なので問題なければ起動します。
インスタンスが利用可能な状態になったら接続から ssh のコマンドをコピペして ssh します。
ssh に成功すると以下のような画面になります。
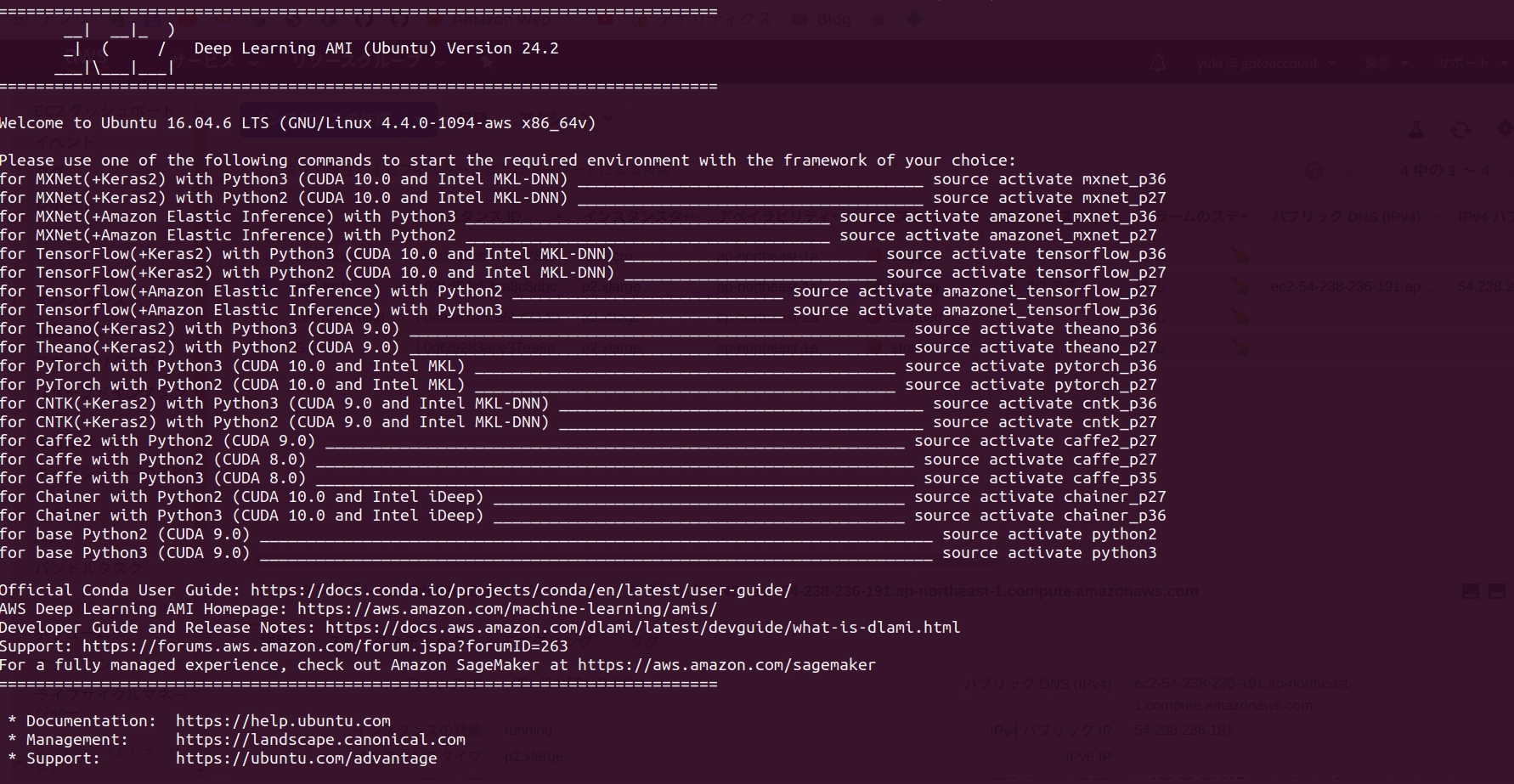
この画面にあるように、自分の使いたい環境に応じて、source activate <環境名>と入力すると対応する環境で作業ができます。
自分の場合は pytorch 環境を使いたかったのでsource activate pytorch_p36と入力しました。
jupyter もインストールされているので、以下のコマンドを入力してトークンを取得します。
jupyter notebook --ip=0.0.0.0 --no-browser --allow-rootすると、以下のような出力がでるので、インスタンス ip のところに EC2 インスタンスの ip アドレスを入力してブラウザで開くと jupyter が使えます。
http://<インスタンスip>:8888/?<トークン>
あとは git clone などするだけですぐに開発が開始できます!
と、思ったのですが、、、
ハマったところ
git clone でコードをダウンロードして、テスト用の画像データでもダウンロードして簡単な機械学習を試してみようと思っていました。
しかし、dataset の読み込みに失敗。。。
エラーをみると storage に space がないとのこと。
え???
EBS はデフォルトだと 75GiB だったような、、、
df -hT /dev/xvda1コマンドでストレージの使用率を調べてみた。

何もしてないのに 70G 使われている?? (※ git clone はしてない状態です)
どうりでスペースが足りないわけです。
調べてみると、一応公式に対策が書いてありました。
以下のようにリストで確認して、必要のないものを2つめのコメンドで削除してねってことだと思います。
conda env list
conda env remove –name <env_name>ただし、この2つめのコマンドはうまくいかなかったです。
実行すると以下のようにconda-env: error: unrecognized arguments:とでてきます。

以下のように入力するとうまくいきます。
conda env remove --name <env_name>この作業を繰り返していくと使えるスペースは増えていきます。
めんどうなので以下のようなスクリプトを使いました。
#!/bin/sh
conda env remove --name amazonei_mxnet_p27 -y
conda env remove --name amazonei_mxnet_p36 -y
conda env remove --name amazonei_tensorflow_p27 -y
conda env remove --name amazonei_tensorflow_p36 -y
conda env remove --name caffe_p27 -y
conda env remove --name caffe2_p27 -y
conda env remove --name caffe_p35 -y
conda env remove --name chainer_p27 -y
conda env remove --name chainer_p36 -y
conda env remove --name cntk_p27 -y
conda env remove --name cntk_p36 -y
conda env remove --name mxnet_p27 -y
conda env remove --name mxnet_p36 -y
conda env remove --name python2 -y
conda env remove --name pytorch_p27 -y
conda env remove --name tensorflow_p27 -y
conda env remove --name theano_p27 -y
conda env remove --name theano_p36 -ypython3 と pytorch_p36 以外は全部消しました。
その結果、容量は70G→43Gに減少しました!

これで dataset 問題は解消できました!
まとめ
AWS の深層学習用 AMI は、情報も多くあってそんなに悩まずに始められるのが良い点だと思いました。
ローカルとほぼ同じ環境を再現できるのが個人的にグッドです。
ただしお金はかかるので、Google Colabratory などの無料サービスとうまく使い分けたいところです。
後半に書いた容量問題はちょっといやですね。
3GB しかデフォルトで使えないとなると使いづらいです。 EBS の容量追加はなるべくしたくないですし。。
本当は、EC2 起動時のユーザデータでスクリプト実行したかったのですが、conda コマンドがないよーとエラーになっていたのであきらめてしまいました。
いい方法があればぜひ教えてください!
Amazon EC2
Amazon EC2 (Elastic Compute Cloud)は AWS における仮想サーバのこと。特徴としては簡単にサイズ変更ができることである。ここでいうサイズとはコンピューティングリソースのことである。よく聞く EC2 インスタンスのインスタンスとは、物理サーバ上に建てられた仮想的なコンピューのことを指す。下記に AWS で挙げられているインスタンスの説明をのせておく。
インスタンスとは AWS クラウドにある仮想サーバーです。 引用:インスタンスの作成
また、この EC2 インスタンスは AZ サービスにあたる。
EC2 インスタンスの作成
インスタンスの作成は次の手順で行われる。
- Amazon Machine Image (AMI)の選択
- インスタンスタイプの選択
- ネットワーク / IAM ロール / ユーザデータなどの設定(インスタンスの詳細設定)
- ストレージクラスの設定
- タグ付け
- セキュリティグループの設定
- 設定の確認
- キーペアの選択
3のユーザデータとは、OS の起動スクリプトのようなもので、EC2 インスタンスの初回起動時に実行したい処理を設定する。ユーザデータを設定する時点では決まっていないデータを用いるためには、メタデータを用いる。メタデータは EC2 インスタンスに関するデータである。
EBS とインスタンスストア
EC2 に接続できるブロックストレージには次の二種類がある。
- Amazon EBS (Elastic Block Store)
- AZ サービス
- 不揮発性
- インスタンスストア
- 揮発性
EBS は、AZ 内に作成されるネットワーク接続型のブロックストレージで不揮発性である。一方、インスタンスストアは EC2 インスタンスの物理ホストの内臓ストレージで揮発性である。したがって、EC2 を落としても失いたくないデータは EBS に保存しておく。ただし、インスタンスストアの情報が失われるのは、自身でデータを削除する場合、停止時、EC2 インスタンスの削除時である。再起動の場合には失われない。
さらに、EC2 インスタンスストアには次の二種類がある。
- EBS-backed インスタンス
- 停止、起動、再起動、削除ができる
- instance store-backed インスタンス
- 再起動と削除のみできる
EBS のタイプ
EBS には、汎用 SSD、Provisioned IOPS SSD、スループット最適化 HDD、Cold HDD という 4 つのタイプがある。(2019/2/17 日時点)
参考:EBS
4 つの違いはパフォーマンスとそれに関わる料金である。 性能としては、Provisioned SSD のほうがもっとも高く次に汎用 SSD、HDD と続く。
ただし、Provisioned IOPS SSD に関しては業務ネットワークの帯域と EBS の I/O の帯域が競合しているため、性能を出し切れない可能性がある。この対策として、EC2 インスタンスを EBS 最適化インスタンスというタイプで起動する方法がある。 この方法では EBS 専用の帯域が確保されるため、性能が安定する。
EBS スナップショット
EBS は AZ サービスであり、同じ AZ 内の EC2 にのみアタッチできる。別の AZ やリージョンで利用したい場合にはスナップショットを用いる。 EBS ボリュームは任意のタイミングでスナップショットを撮ることができる。スナップショットは S3 に保存される EBS 内のデータのバックアップであり、差分データのみが保存される。スナップショットを取得する際はデータのせ整合性を保つため、ディスク I/O を停止する必要がある。 スナップショットから EBS を復元する場合は異なる AZ やサイズの EBS を指定して復元できる。
この EBS は AZ サービスというところと、EFS との使い分けは理解する必要がある。